Інформаційні системи в аграрному менеджменті (1999)
6.2. Автоматизований банк даних
Банк даних — це людино-машинна система з відповідно організованими даними та технічними, програмними, мовними і організаційно-методичними засобами для забезпечення централізованого накопичення і колективного використання даних. БнД здійснює формування, коригування і зберігання всіх даних, необхідних для управління об’єктами, забезпечує багаторазовий і швидкий доступ до даних в процесі рішення задач.
В основу розробки БнД покладені такі принципи:
єдність структурно-інформаційної організації масивів у БнД;
одноразове введення первинної інформації з наступним комплексним її використанням;
централізація накопичення, зберігання і обробки даних;
робота з даними в різних режимах;
оперативність доступу до даних.
Банки даних за доступністю можуть поділятися на такі класи: загальнодоступні і з обмеженим колом користувачів; за ознаками використовуваних у них БД — на такі класи:
локальні, загальні і розподілені;
документальні, фактографічні і лексикографічні;
ієрархічні, мережні, реляційні і т. ін.
У структурному розумінні БнД складається з таких основних компонентів як база (бази) даних і система управління базами даних (СУБД) (рис. 6.3). Як людино-машинна система БнД включає у свою структуру також адміністратора системи, що відповідає за її функціонування (людина чи колектив людей), інтерфейс користувача (засоби зв’язку з користувачем).
Ядром БнД є база даних, що складається з масивів даних і описує предметну область. У ній нагромаджуються, поновлюються і зберігаються дані.
Як уже зазначалося, за видом даних БД поділяються на структуровані, частково структуровані і неструктуровані, а структуровані — на ієрархічні, сіткові (мережні), реляційні (рис. 6.4) та інші (змішані, мультимодельні). Ця сама класифікація відповідно стосується й до СУБД.
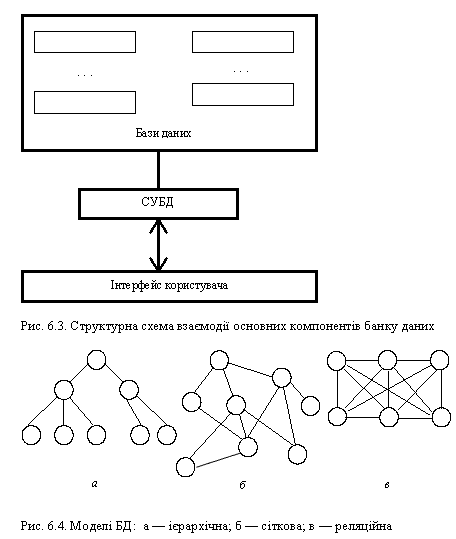
В ієрархічній моделі БД дані організовані в суворій підпорядкованості у вигляді дерева типів елементів даних чи типів сегментів. Для пошуку даних вказуються всі пошукові елементи за принципом згори вниз і зліва направо. При збільшенні ієрархічних рівнів виникають труднощі при пошуку, коригуванні, додаванні і вилученні записів.
У сітковій моделі БД дані організовуються записами, пов’язаними відповідним ланцюжком у вигляді вузлів і зв’язків. Породжений вузол у структурі даних пов’язаний більш ніж з одним початковим вузлом, а тому така модель складна для сприйняття і недостатньо забезпечує незалежність даних (хоч вузли та їх елементи легко додаються і вилучаються).
У реляційній моделі БД зв’язки і дані мають вигляд системи відношень. Ієрархічна структура відображається у вигляді двовимірної таблиці. Тепер такі БД найрозповсюдженіші (DEBASE, CLIPPER, FOXPRO і т. ін.)
Для спілкування користувачів з БнД призначені мовні засоби, які описують різні компоненти БнД. Мовні засоби включають мови опису даних, мови спілкування з БД та інші мовні засоби.
Взаємодію всіх частин інформаційної системи в процесі її функціонування забезпечують програмні засоби, які разом з мовними засобами і створюють СУБД. У сучасних умовах широкого розповсюдження локальних обчислювальних мереж потрібні потужні СУБД, які могли б забезпечити зручний і гнучкий інтерфейс управління вікнами, можливість ведення (ввід, дозапис, вилучення, друк) і підтримки розподілених БД та програм (на сервері і робочих станціях), переміщення додатків і швидкодію їх використання, використання різних мов програмування, єдність стандартних запитів (SQL), працездатність на робочих станціях з мінімальною пам’яттю і обладнанням.
Технічною основою БнД є процесори, пристрої введення/виведення даних, зовнішні запам’ятовуючі пристрої, система зв’язку.
Нормативно-технологічні та інструктивно-методичні матеріали з організації й використання БнД є організаційно-методичними засобами БнД.
Відомості про предметну область та її інформацію, зміст і структуру БД, зв’язок між елементами БД і програмами забезпечує словник даних.
Оскільки останнім часом у багатьох системах створюються також бази знань (БЗ), то окремі автори вважають доцільним замість терміну «банк даних» використовувати термін «інформаційний банк», включаючи в структуру такого банку окрім БД і БЗ.
Процес створення БнД проходить відповідні етапи, на кожному з яких він набирає форми певної моделі (рис. 6.5).

На інфологічному (інформаційно-логічному) рівні вказується, що повинна мати і обробляти проектована система, не торкаючись конкретних питань її реалізації. Інфологічна модель (ІЛМ) — це опис предметної області, виконаний без орієнтації на використовувані подальші програмні та технічні засоби. Мета інфологічного моделювання — створити в міру точне і повне відображення реального об’єкта інформації для подальшого використання при побудові БнД.
ІЛМ повинна адекватно відображати предметну область мовою, зрозумілою як спеціалісту предметної області, так і адміністратору БнД, забезпечити однозначне трактування моделі і бути динамічною. Вибір мовних засобів при цьому — нелегке завдання, оскільки вони мусять бути досить потужними і гнучкими для опису різних предметних областей і одночасно простими у використанні.
У процесі створення ІЛМ виконується інформаційний аналіз (з використанням різних методів), виділення і опис об’єктів, опис зв’язків між об’єктами, опис процесів та даються інші відомості (довжина реквізитів і т. ін.).
ІЛМ, які дають уявлення адміністратору БнД і користувачам про предметну область, називають ще концептуальними моделями.
Датологічна (внутрішня) модель БД є подальшою орієнтацією логічної моделі предметної області на конкретну СУБД. Тому при створенні датологічної моделі потрібно добре знати особливості конкретної СУБД, обмеження і фактори, що впливають на вибір логічних структур даних.
При ручному проектуванні побудову датологічної моделі починають з графічного подання структури БД , оскільки воно наочніше. У разі автоматизованого проектування — навпаки, спочатку одержують аналітичне подання структури, а потім за ним відтворюється графічне уявлення.
При проектуванні датологічної моделі виділяється мінімальна логічна одиниця (елемент даних, поле і т. ін.), здійснюється групування елементів у структури вищих рівнів і визначаються зв’язки між ними з урахуванням обмежень СУБД, ресурсів і потреб користувачів, установлюються зв’язки не лише між відповідними сутностями предметної області, а й зв’язки, що виникають у процесі обробки інформації у БД. Великий вплив при цьому на датологічну модель можуть мати можливості фізичної організації даних.
Суть фізичної моделі БД полягає у відображенні датологічної моделі в середовищі зберігання з урахуванням можливостей СУБД і фізичної організації даних. При цьому вибираються методи доступу, розміри елементів запису і т. ін. Параметрами оцінки фізичної моделі є обсяг необхідної пам’яті для БД, обсяг оперативної пам’яті, час для виконання запитів. Інтегрований показник — вартість обробки даних.
У сучасних ЕОМ вирізняють кілька методів обробки даних і їх організації у файли, які у своїй сукупності утворюють методи доступу до даних. Основними методами доступу до даних є послідовний, індексно-послідовний і прямий.
Суть послідовного методу доступу полягає в тому, що записи розміщуються послідовно і n –й запис можна прочитати лише після того, як будуть прочитані записи, що йдуть перед ним. Послідовну організацію даних можуть мати файли на будь-яких машинних носіях. При цьому забезпечується економія пам’яті, але сповільнюється обмін інформацією. Послідовний метод доступу до даних ефективний при обробці значної частини інформаційного масиву.
Прямий метод доступу дозволяє безпосередньо звертатися до потрібного запису і тому є найшвидшим. Метод жодних обмежень на структуру файла не накладає, проте програміст мусить своїми засобами описувати конкретну адресу кожного запису. Це пов’язано не лише із труднощами програмування, а й зі значними витратами машинних ресурсів на адресацію записів. Метод переважно застосовується у системах реального часу. Може використовуватися на магнітних барабанах та різних типах дисків, які тому й називаються носіями прямого доступу.
Індексно-послідовний метод передбачає виокремлення на машинному носієві двох зон: зони індексів і робочої зони. У зоні індексів розміщуються упорядковані ключі записів (наприклад, табельні номери працюючих), а в робочій зоні в порядку розміщення ключів — власне записи (наприклад, дані про відпрацьований час і заробіток кожного працюючого). Це дозволяє ЕОМ у невеликій зоні індексів швидко знайти потрібний індекс (код), а за ним у робочій зоні уже й відповідний йому запис. Метод доступу дещо повільніший від прямого, але значно швидший від послідовного, хоч самі записи також розміщуються послідовно. Зчитування можливе в будь-якому порядку, забезпечується швидке коригування записів. Метод використовується лише на носіях прямого доступу.
Як різновид послідовної і індексно-послідовної організації даних на практиці використовується також бібліотечна організація даних і метод доступу до них. У цьому разі набір даних складається з пойменованих розділів (файлів), усередині яких дані розміщені послідовно, і окремої ділянки носія зі змістом. У змісті набору даних містяться імена всіх розділів набору даних та їх адреси. У результаті доступ до будь-якого розділу бібліотеки здійснюється безпосередньо за його ім’ям. Така організація даних використовується для зберігання програм і таблиць, кожна з яких має своє ім’я.
Записи в файлах можуть мати формат фіксованої, змінної чи невизначеної довжини (на перфокарткових пристроях — тільки фіксованої довжини). На магнітних стрічках і різних видах дисків записи можуть бути зблоковані і незблоковані. Зблоковані записи суттєво підвищують швидкість зчитування/запису даних і економлять зовнішню пам’ять за рахунок зменшення проміжків.
Важливе значення для підвищення ефективності машинної обробки економічної інформації має структуризація інформаційних масивів на масиви з постійною і змінною інформацією, а також на більш конкретні їх різновиди. Як уже зазначалося, виділення масивів з постійною інформацією дозволяє вилучати з первинних документів ряд реквізитів, автоматизувати виконання ряду операцій, які раніше виконувались вручну, спрощувати документообіг.